正则表达式(Regular Expression,在代码中常简写为regex、regexp或RE)使用单个字符串来描述、匹配一系列符合某个句法规则的字符串搜索模式。搜索模式可用于文本搜索和文本替换。
各个编程语言中都支持正则表达式
正则表达式的用途有很多,比如:
- 表单输入验证
- 搜索和替换
- 过滤大量文本文件(如日志)中的信息
- 读取配置文件
- 网页抓取
- 处理具有一致语法的文本文件,例如 CSV
基本语法
找一个在线的正则表达式,把语法掌握,然后再到具体的编程语言中
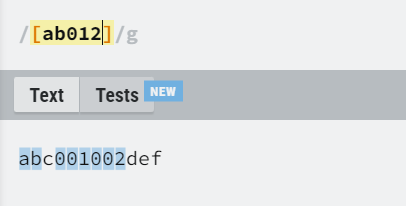
字符集合
使用“[]”
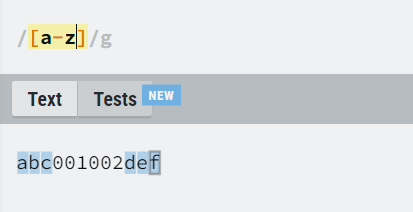
字符范围
使用“-”
中文:[\u4e00-\u9fa5]
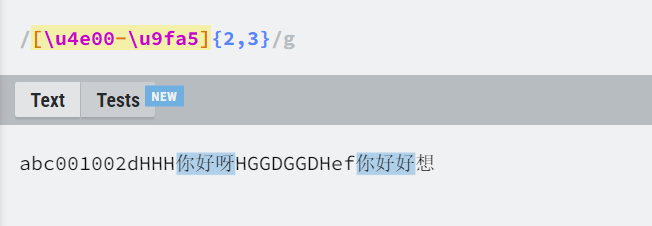
数量字符
{m,n}
最少匹配m个,最多匹配n个
+:匹配前面一个表达式一次或者多次,相当于{1,}。

*:匹配前面一个表达式0次或者多次,相当于{0,}。

?:单独使用匹配前面一个表达式零次或者一次,相当于{0,1},
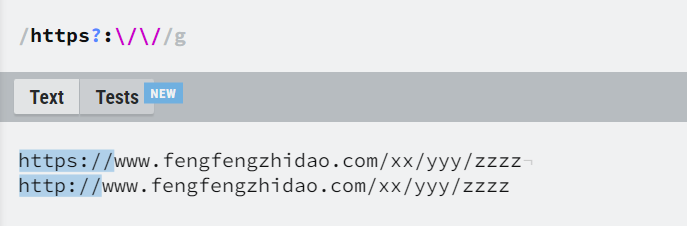
贪婪模式
正则会尽可能的匹配多的字符
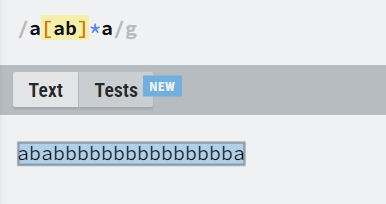
非贪婪模式
尽可能匹配少的

元字符
| 元字符 | 说明 |
|---|---|
| \d | 匹配数字 |
| \D | 匹配非数字 |
| \w | 匹配数字、字母、下划线 |
| \W | 匹配非数字、字母、下划线 |
| \s | 匹配任意的空白字符 |
| \S | 匹配任意的非空白符 |
| . | 匹配除换行符之外的任意字符 |
特殊字符
| 特殊字符 | 说明 |
|---|---|
| . | 匹配除了换行符之外的任何单个字符 |
| |将特殊字符转义 | |
| [^] | 取非,匹配未包含的任意字符 |
位置匹配
| 位置字符 | 说明 |
|---|---|
| \b | 匹配一个单词边界,也就是指单词和空格间的位置。 |
| \B | 匹配非单词边界。 |
| ^ | 匹配开头,在多行匹配中匹配行开头。 |
| $ | 匹配结尾,在多行匹配中匹配行结尾。 |
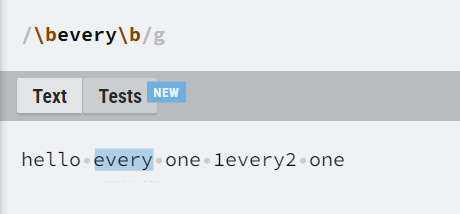
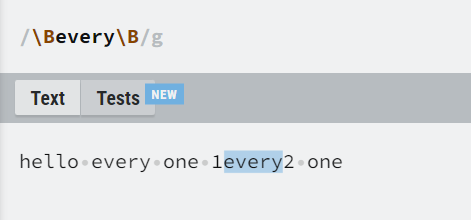
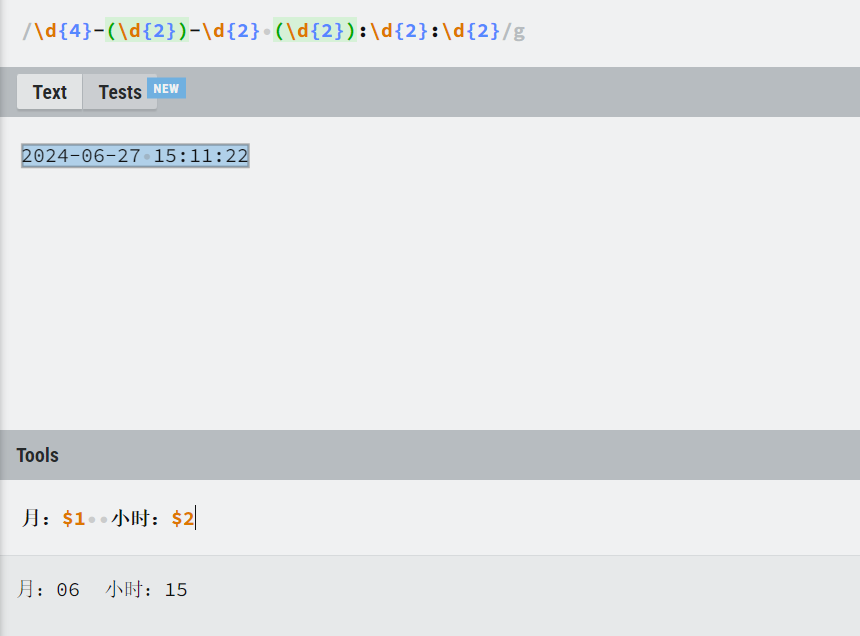
分组
使用小括号
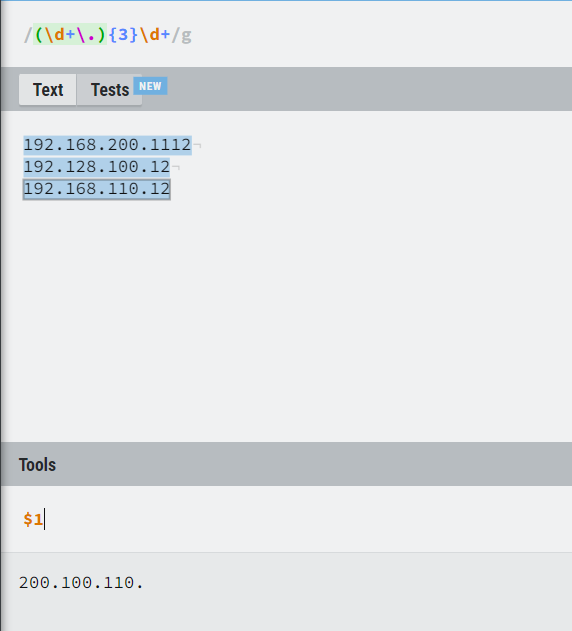
捕获分组
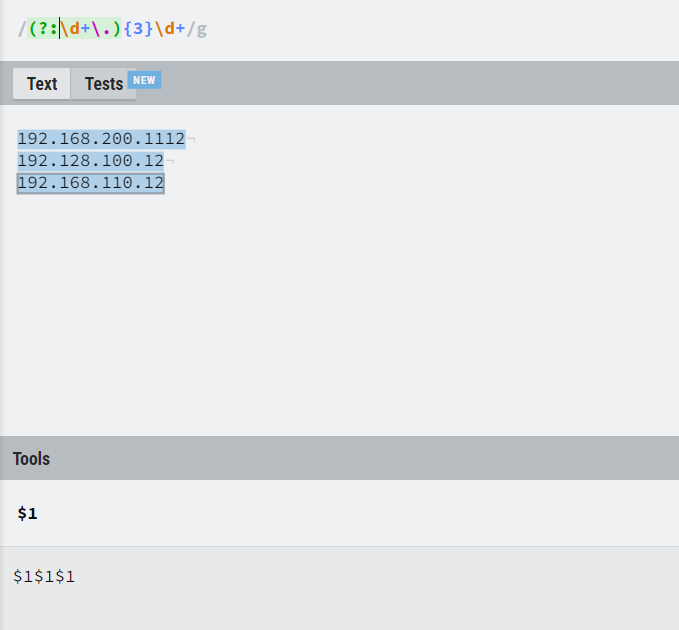
无捕获分组
有些时候,使用小括号只是希望把它当做一个整体,不希望分组
修饰符
| 修饰符 | 说明 |
|---|---|
| g | 表示全局匹配,即在整个字符串中搜索所有匹配项,而不仅仅是第一个匹配项。 |
| i | 表示在匹配时忽略大小写。 |
| m | 表示多行模式,在这种模式下,正则表达式可以同时匹配每一行的内容,而不仅仅是整个字符串。 |
| u | 表示在匹配时进行完全递归,这样可以处理一些较为复杂和嵌套的情况。 |
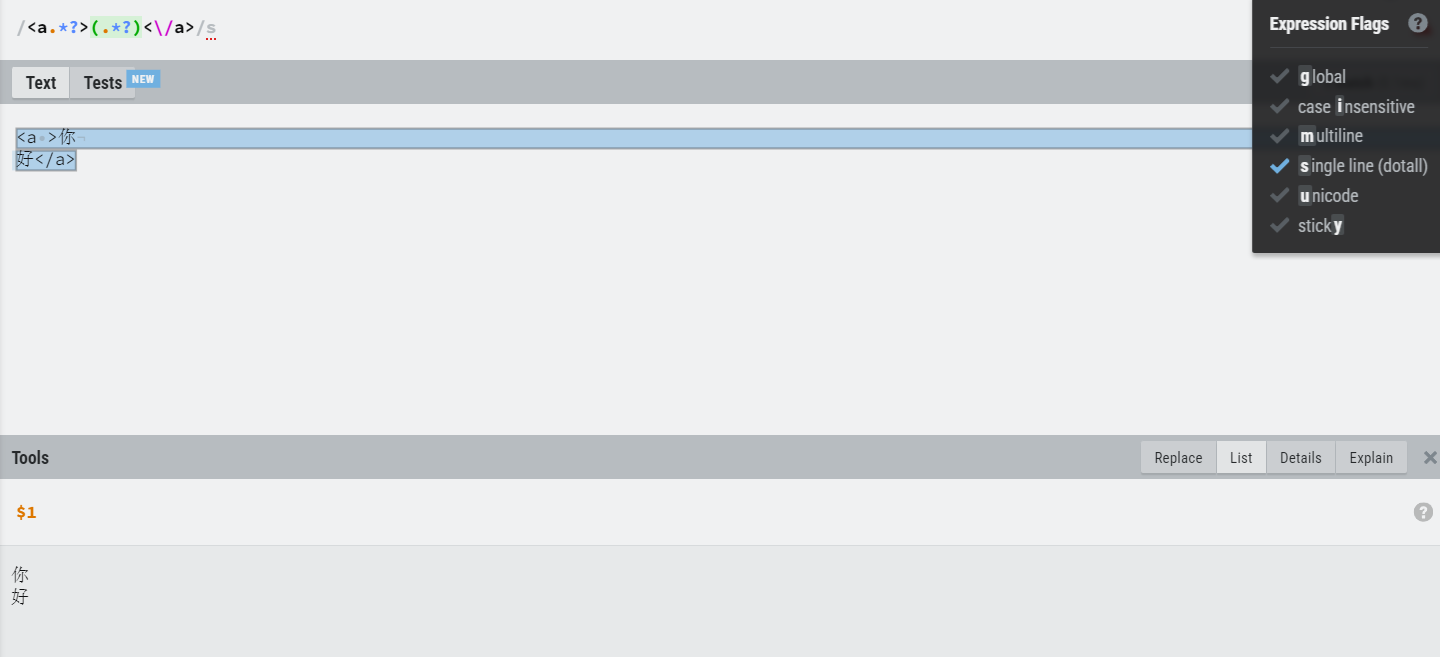
| s | 在默认情况下,.元字符匹配除了换行符之外的任意字符。但是在设置了s修饰符后,.元字符也会匹配换行符。 |
m模式
主要影响^和$符合的行为


s模式
点号可以匹配换行