概述
大模型开发涉及一系列核心概念和技术,理解这些基础概念是进行大模型应用开发的前提。
本文将介绍几个关键概念
现在所有大语言模型,本质都是“文本概率猜谜高手”——它不会思考、不会操作电脑/手机等外部环境,只会根据海量文本训练的经验,猜下一个词、下一句话最可能是什么,就像我们玩成语接龙,顺着前面的词猜下一个最贴切的,只不过它的“词汇量”和“猜谜经验”比我们多亿倍。
LLM

早期的语言模型,就像刚学说话的小孩,你问它“今天吃什么”,它可能只会蹦出“吃”“饭”两个字,逻辑混乱、答非所问,简直就是“人工智障”
后来工程师给它喂了全世界的书籍、文章、对话(海量文本数据),把它的“大脑参数”从几百万调到千亿级,它突然就“开窍”了——能写作文、聊八卦、写代码、翻译外文,甚至能陪你吐槽,这种“突然变聪明”的现象,就是大模型的“智能涌现”
为了和之前的“笨模型”区分开,就有了“大语言模型”(LLM Large Language Model大语言模型)。
Context
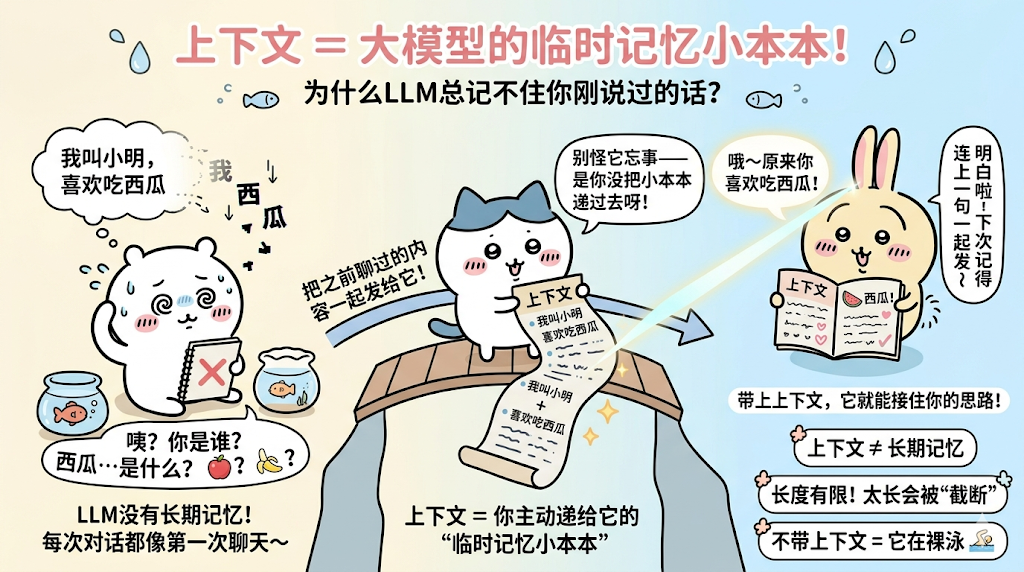
别看LLM很厉害,但它有个致命缺点:记不住事——就像鱼的记忆,转头就忘,每次和它对话,它都以为是“第一次聊天”。
举个例子:你跟它说“我叫小明,喜欢吃西瓜”,然后问它“我喜欢吃什么”,如果不把前面的话告诉它,它就会瞎猜“苹果”“香蕉”;但如果你把“我叫小明,喜欢吃西瓜”这句话一起发给它,它就知道“哦,你喜欢吃西瓜”——这些“一起发过去的、之前聊过的内容”,就是上下文(Context)。
简单说,上下文就是给大模型的“临时记忆小本本”,每次对话都要把之前的内容记在本子上递给它,它才能跟上你的思路,不犯“失忆”的错误。
Prompt
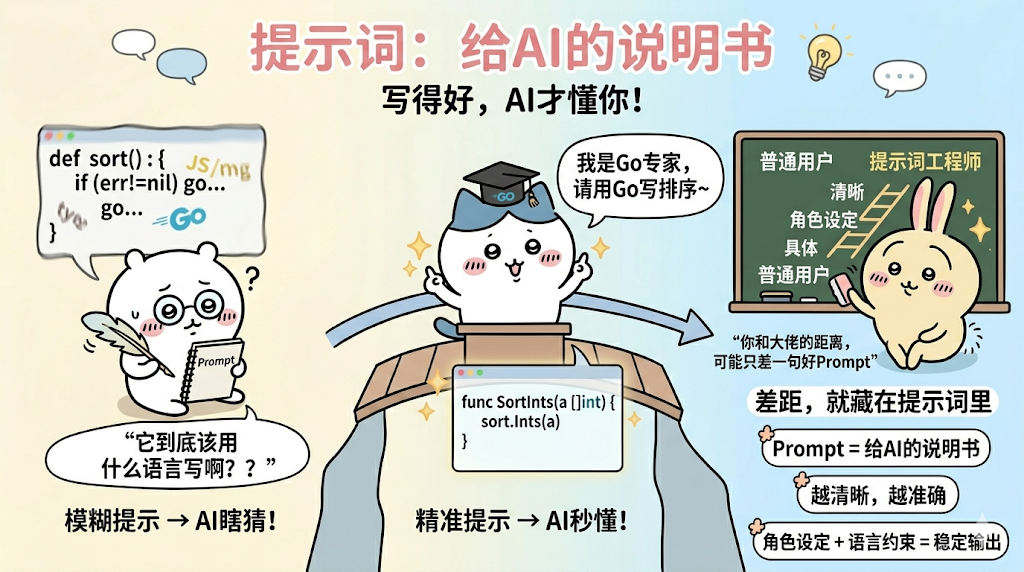
Prompt 就是提示词,简单说就是你告诉大模型“该做什么、怎么做”的指令,相当于给它的“说明书”——说明书写得越清楚,大模型做得越到位;写得模糊,它就会瞎猜、做错。
比如你让ai写一个排序的函数,ai写出来的可能用什么语言的都有
这个时候你再加一个 “你是精通go语言的专家,后续所有问题涉及的编程语言,都使用go语言编写”这个提示词,那么你再问他,写一个排序函数,那就是精确用go语言写的了
提示词工程可是一门很庞大的学问,可以这么说,你和大佬们的差距基本上就在提示词的编写上了
RAG
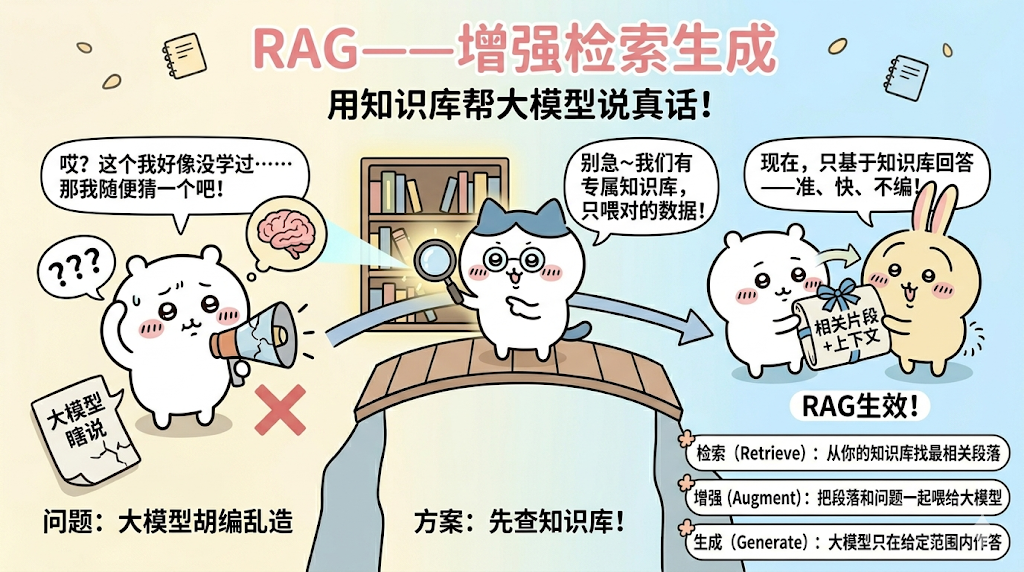
有时候大模型遇到不知道的知识就会瞎说,那可以自己搞一个知识库,问之前先在我们自己的知识库里面查一下相关的数据,然后把关联的数据一起发给大模型,让他只能在这个知识库里面回答问题,这就是是RAG——增强检索生成
Agent

普通大模型(LLM)更像一个被动应答的工具:
- 只能在网页、软件里一问一答
- 帮你写文案、写代码、回答问题
- 输出结果后,需要你手动复制、粘贴、执行、调试
- 它不会主动感知环境,也不会自己动手操作
而LLM Agent(智能体)是在大模型基础上,增加了自主行动能力:
- 能通过程序理解任务目标
- 可以调用工具:读取文件、查询外部信息、联网搜索、写入文件、执行代码、操作数据库等
- 遇到问题会自己规划步骤、调用工具、试错、修正
- 不需要你全程手动复制粘贴,能直接在你的项目、环境里完成工作
Claude Code、Cursor、GitHub Copilot Workspace 这类能直接读写你项目文件、自动修改代码的工具,本质上就是面向编程场景的 LLM Agent。
Function Calling
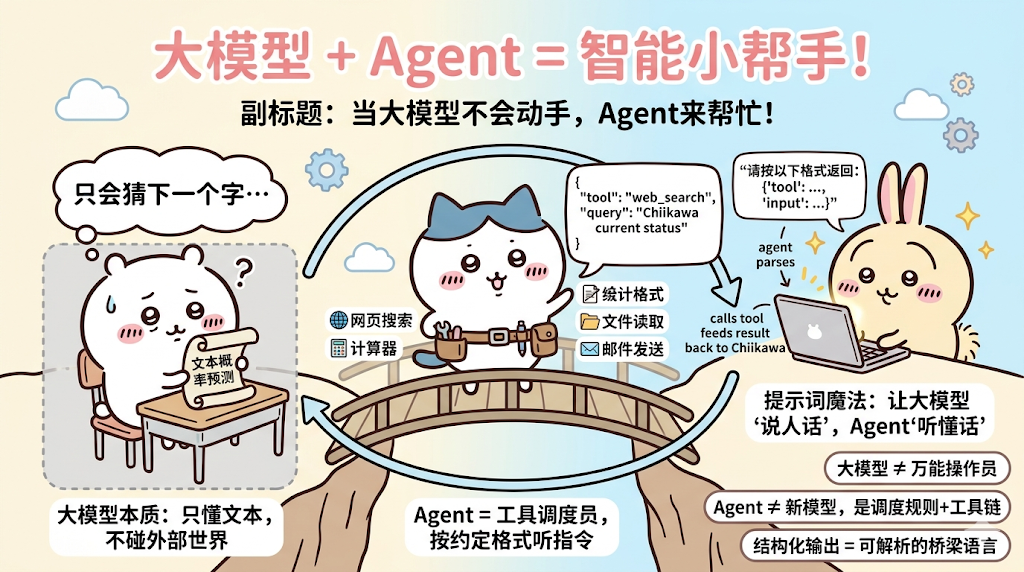
前面说过,大模型本质是“文本概率预测”,不会操作外部环境
我们可以通过agent完成这些事情,但是问题来了,agent怎么知道什么时候我该调用哪一个工具,什么时候我要去访问网页呢
那么可以在问大模型问题的时候,加一个提示词,“如果需要调用什么工具,安装特定格式返回内容,我有以下的工具可以使用......”,然后大模型输出的时候,agent按照自己约定的格式去进行解析,然后调用工具,再把调用工具输出的内容再返回大模型
MCP
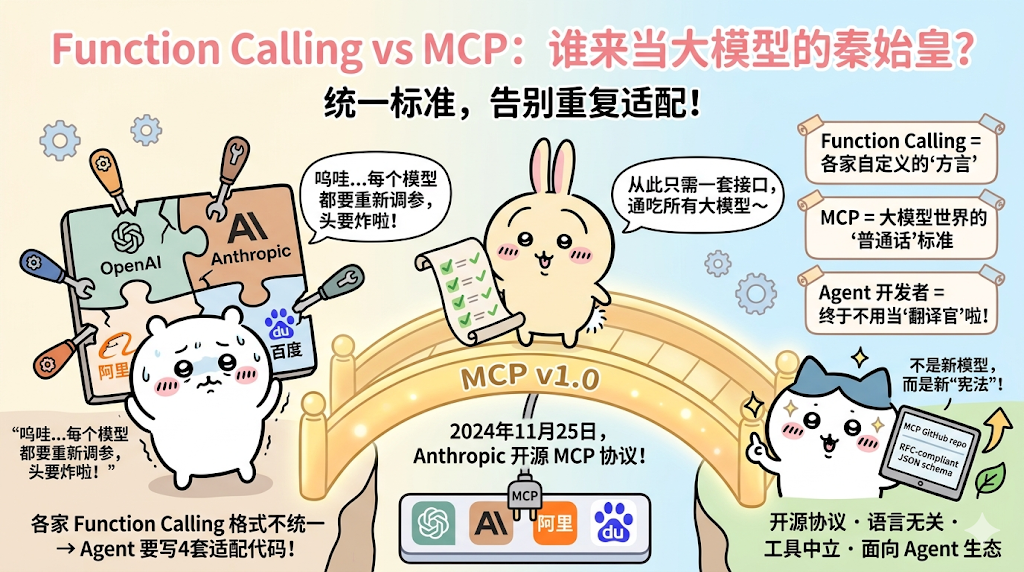
上面说的 Function Calling 只是大模型输出结构化指令的一个概念,具体怎么定义、用什么格式,每家厂商(OpenAI、Anthropic、阿里、百度等)实现都不一样。
这样一来,如果 Agent 想兼容所有大模型,就要挨个适配,非常麻烦。所以这时候就需要一个 “秦始皇” 来统一标准。
于是Anthropic 在 2024 年 11 月 25 日正式推出并开源了 MCP(Model Context Protocol,模型上下文协议),用来统一大模型与外部工具、系统之间的交互规范,让 Agent 不用再为每家模型单独适配。
Skill
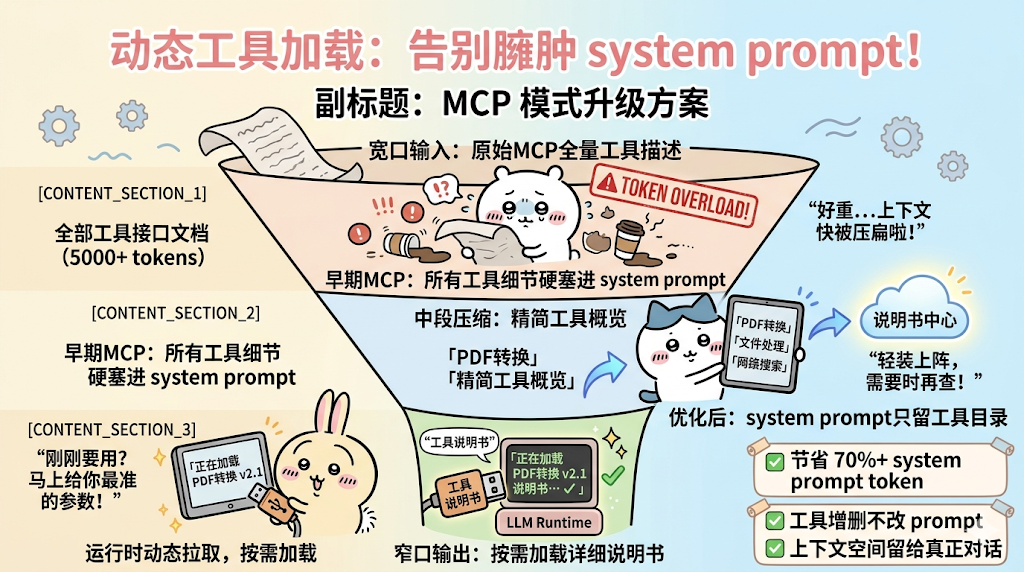
早期 MCP 模式需要把所有已配置的工具能力、接口信息全都塞进 system prompt 一起发给大模型。先不谈其他问题,光是这些描述就会消耗巨量 token,成本高、效率低,还会挤占上下文空间。
为了解决这个问题,就把各类工具能力(比如 PDF 转换、文件处理、搜索等)抽离出来,做成独立的标准化模块。在 system prompt 里,只需要简单告诉大模型:有哪些工具、大致能做什么,不需要把所有接口、参数、调用方式一次性全部塞进去。
等到真正对话过程中,大模型判断需要用到某个工具时,再通过协议动态去拉取该工具的详细说明书,按需加载、按需调用。
这样既节省了大量 token,又让工具扩展更灵活,系统也更轻量。

