什么是orm
之前我们操作数据库是直接在命令行中敲sql语句
查全部数据库:show databases;
查询一张表下的全部记录: select * from 表名;
如果后面有条件就跟where...
我们把战略放远一点,在实际的网站开发过程中,对于数据库的选择不可能只是mysql, 可能会有其他的数据库,每一个数据库对应的sql语句都会有相应的差异
目前主流的数据有:MySQL Oracle SQLServer sqlite
每一个数据库的语法都会有差异,所以我们不能直接写sql语句
而是找一个上层的方法
例如:在python中操作mysql,是使用了pymysql这个库,不过最终还是需要我们直接写sql语句, pymysql还是不够上层
所以诞生了orm
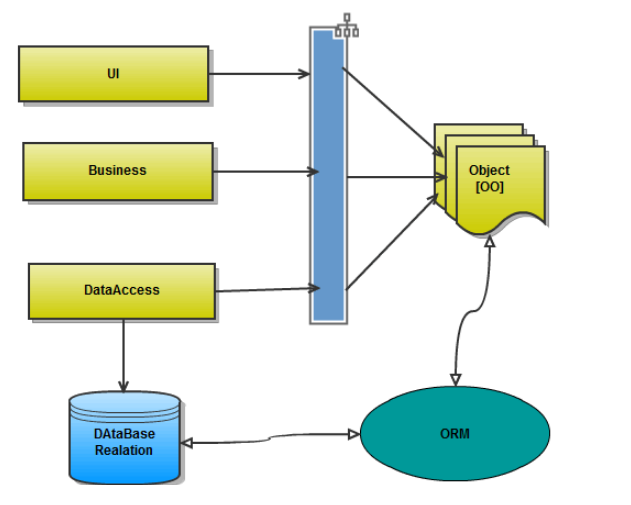
orm是数据库的上层,我们只负责调用函数,orm底层会把它翻译成对应的sql语句
生成表模型
好了,现在明白了orm的作用,我们开始做些有意义的申请
在我们学习mysql的时候,我们需要建库建表,并且在建表的时候需要写上字段这些信息
create table student(
nid int primary key auto_increment, # 主键,自动增长
name varchar(8), # 姓名
age int, # 年龄
gender enum('男', '女'), # 性别
addr varchar(32) # 住址
);
熟悉一下mysql的建表操作
但是在orm中,我们不需要这样去写sql语句了
而是去写一个类
一个类对应一张表
在对应app的models.py中创建
from django.db import models
class Student(models.Model):
nid = models.AutoField(primary_key=True)
name = models.CharField(max_length=8, verbose_name='学生姓名')
age = models.IntegerField(verbose_name='学生年龄')
gender = models.CharField(max_length=1, verbose_name='学生性别', default='男')
addr = models.CharField(max_length=32, verbose_name='学生地址', null=True, blank=True)
在这里我创建了一个类
类名:Student => 表名
类属性:name... => 表中字段
参数:
max_length:该字段的最大长度,超过会报错verbose_name: 字段的名称,后面讲后台系统会用上default:如果不赋值,会使用这个默认值null:该字段可以为空blank:后台创建的时候可以为空
现在我们创建类之后,还不能直接用它,需要将它变成实际的数据表
这一步操作被称为:数据库迁移
数据迁移之前的操作
在django中,自带了一个数据库,sqlite,在做小项目的时候使用sqlite
相对来说比较方便
在配置中可以修改你用的数据库
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.sqlite3',
'NAME': BASE_DIR / 'db.sqlite3',
}
}
# 默认是使用 sqlite
如果需要改成mysql
# 在 settings文件中
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.mysql',
'NAME': 'cnblog', # 你的库名,需要自己创建一个数据库
'USER': 'root', # 用户名
'PASSWORD': 'root', # 密码
'HOST': '127.0.0.1', # 后面两个默认即可
'PORT': 3306
}
}
还需要在对应app的init.py文件中加入:
# 你需要操作什么数据库就需要导入对应的第三方模块
import pymysql
pymysql.install_as_MySQLdb()
配置没问题之后就可以进行数据库迁移了
我们使用sqlite进行演示,后续再使用mysql
python manage.py makemigrations
# 会在你的app下的migrations目录下生成一个py文件,这个就是记录要转换的详细信息
# 如果你发现你执行这个指令无效,就把除init之外的文件都删掉
python manage.py migrate
# 实际的建表操作,包括字段的更改,表的更改
这两步一般一起操作
执行这步操作之后,就会出现一个db.sqlite3的文件,这就是一个数据库
双击就可以打开

其他的表是django为我们创建的,我们这个时候先不管它
这张表的名称是: app名称_小写类名
添加记录
ok,建表完成之后我们就需要对表添加数据了
再回忆一下sql语句是什么
insert into student value ('王富贵', 21, '男', '北京市');
还是那句话,在orm中只是一个函数的事情
添加一条记录有两种方式
添加记录方式 1(使用对象.save)
from django.shortcuts import HttpResponse
from app01.models import Student # 导入我们创建的这个类
def add(request):
student_obj = Student(name='王富贵', age=23, addr='南京市')
# 实例化一个对象
student_obj.save()
# 调用这个对象的 save方法进行添加记录
return HttpResponse('ok')
添加记录方式 2(使用create方法)
from django.shortcuts import HttpResponse
from app01.models import Student # 导入我们创建的这个类
def add(request):
# 添加一条记录
student_obj = Student.objects.create(name='张三', age=12, addr='北京市')
print(student_obj)
return HttpResponse('ok')
我们使用关键字进行传参,如果不赋值就不传参 十分灵活
如果需要批量添加数据,我们有两种可选方案
第一种批量添加
使用for循环,批量执行create操作
from django.shortcuts import HttpResponse
from app01.models import Student # 导入我们创建的这个类
def add(request):
# 批量添加
import random
from faker import Faker
fake = Faker('zh_CN')
for i in range(20):
student_obj = Student.objects.create(name=fake.name(), age=random.randint(14, 26), gender=random.choice('男女'))
return HttpResponse('ok')
这种方式不推荐,数据量少还行,量多就很慢
第二种批量添加
使用对象列表添加
from django.shortcuts import HttpResponse
from app01.models import Student # 导入我们创建的这个类
def add(request):
# 批量添加
import random
from faker import Faker
fake = Faker('zh_CN')
student_list = [] # 用于存放实例化的对象
for i in range(20):
student_obj = Student(name=fake.name(), age=random.randint(14, 26), gender=random.choice('男女'))
student_list.append(student_obj)
# 批量添加的方法
Student.objects.bulk_create(student_list)
return HttpResponse('ok')
这种面对数据量大的情况,速度也是非常快,推荐

