什么是索引
小时候我们查字典,如果不知道这个字大概读什么,可能就得一页一页翻字典
如果知道这个字的大概读音,翻字典的时候就直接到那一片区域去找
为什么需要索引?
想象你有一张files表,里面存了 1000 万行数据。如果你执行:SELECT * FROM files WHERE file_name = '秘密文件.zip';如果没有索引,数据库得从第 1 行扫到第 1000 万行(全表扫描),你的硬盘灯会闪个不停,用户等到天荒地老。
场景:你的“枫枫网盘”用户量激增,查询文件名变得极慢。
-- 1. 创建演示表
CREATE TABLE cloud_files (
id BIGINT GENERATED BY DEFAULT AS IDENTITY PRIMARY KEY,
file_name TEXT NOT NULL,
file_type VARCHAR(20),
created_at TIMESTAMPTZ DEFAULT NOW()
);
-- 2. 插入 100 万条模拟数据(演示时可以用这个快速生成)
INSERT INTO cloud_files (file_name, file_type)
SELECT
'file_' || i || '.pdf',
(ARRAY['video', 'image', 'doc'])[floor(random()*3)+1]
FROM generate_series(1, 1000000) s(i);
-- 3. 【未加索引前】查询耗时
EXPLAIN ANALYZE SELECT * FROM cloud_files WHERE file_name = 'file_999999.pdf';
-- 你会看到 "Seq Scan" (全表扫描),耗时可能在几十毫秒
创建索引
-- 给文件名加上 B-Tree 索引(最常用的平衡树索引)
CREATE INDEX idx_file_name ON cloud_files(file_name);
-- 再次查询
EXPLAIN ANALYZE SELECT * FROM cloud_files WHERE file_name = 'file_999999.pdf';
-- 你会发现变成了 "Index Scan",速度提升几百倍!
其他类型的索引
-- 显式指定或默认不写都是 B-Tree
CREATE INDEX idx_file_name ON cloud_files USING btree (file_name);
-- 仅适用于 = 查询
CREATE INDEX idx_file_hash ON cloud_files USING hash (file_name);
-- 注意字段顺序:(user_id, file_type) 遵循最左匹配原则
CREATE INDEX idx_user_file_type ON cloud_files (user_id, file_type);
-- 如果你的网盘支持“标签查询”或者存储了 JSON 格式的元数据,GIN 索引是神器。
-- 假设有一个 tags 字段(类型为 TEXT[])
CREATE INDEX idx_files_tags ON cloud_files USING gin (tags);
-- 假设有一个 meta_data 字段(类型为 JSONB)
CREATE INDEX idx_files_meta ON cloud_files USING gin (meta_data jsonb_path_ops);
-- 唯一索引
CREATE UNIQUE INDEX idx_file_md5 ON cloud_files (file_md5);
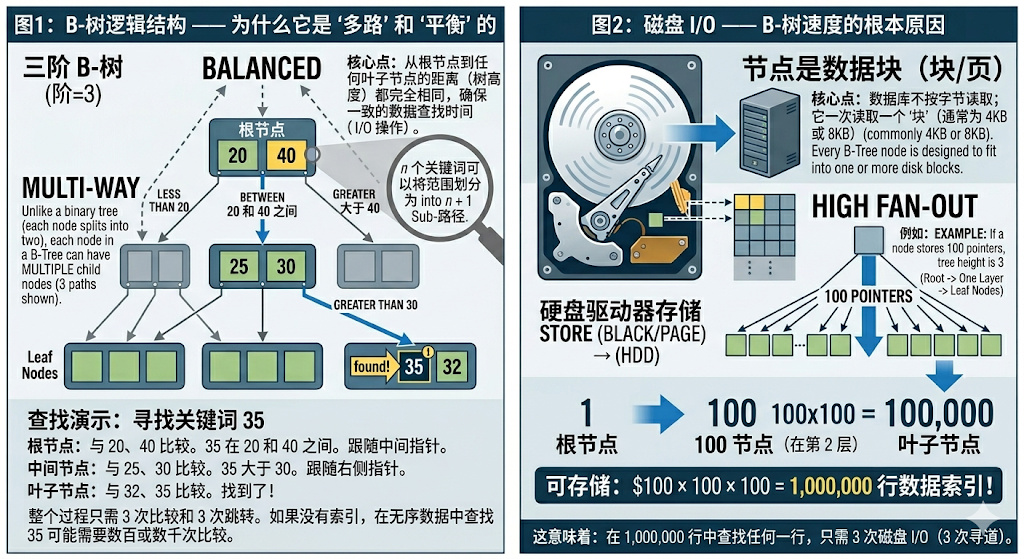
核心底层:为什么 B-Tree 这么快?
CREATE INDEX默认通常是B-Tree 索引。它的核心逻辑是平衡多路查找树。
- **对数级增长:**在 1000 万行数据中,全表扫描需要 O(n) 的复杂度(看 1000 万次);而 B-Tree 索引只需要$log_m(n)$ 的复杂度。
- 实际体感: 哪怕数据量翻了 10 倍达到 1 亿行,B-Tree 的树高度可能只增加了 1 层,查询耗时几乎没有明显变化。
索引的“代价”:天下没有免费的午餐
索引虽好,但不能全表所有字段都加。每一条索引都会带来以下开销:
- 磁盘空间: 索引本身是一棵树,需要占用额外的存储空间。
- 写入性能:当你执行**
INSERT、UPDATE或DELETE**时,数据库不仅要改数据,还要同步更新索引树。索引越多,写操作越慢。 - **维护成本:**随着数据频繁变动,索引可能会产生碎片,偶尔需要
REINDEX(重建索引)来恢复性能。
这些情况下索引会“失效”
很多新手加了索引发现查询还是慢,通常是因为触发了索引失效:
| 场景 | 错误示例 (会导致 Seq Scan) | 正确姿势 |
|---|---|---|
| 模糊查询 | WHERE file_name LIKE '%file_999%'; |
只有“左前缀”匹配file_999% 才能用索引 |
| 函数操作 | WHERE UPPER(file_name) = 'FILE.PDF'; |
建立函数索引或在查询前处理数据 |
| 类型不匹配 | WHERE id = '123'; (id是数字,却传字符串) |
保持类型一致,避免隐式转换 |
| 最左匹配 | 复合索引(a, b)只查b |
复合索引必须从最左侧字段开始匹配 |

